 Overview of MARS
Overview of MARSAbstract
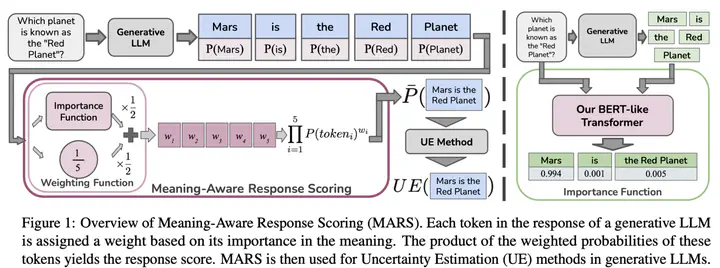
Generative Large Language Models (LLMs) are widely utilized for their excellence in vari- ous tasks. However, their tendency to produce inaccurate or misleading outputs poses a po- tential risk, particularly in high-stakes environ- ments. Therefore, estimating the correctness of generative LLM outputs is an important task for enhanced reliability. Uncertainty Estima- tion (UE) in generative LLMs is an evolving domain, where SOTA probability-based meth- ods commonly employ length-normalized scor- ing. In this work, we propose Meaning-Aware Response Scoring (MARS) as an alternative to length-normalized scoring for UE methods. MARS is a novel scoring function that con- siders the semantic contribution of each to- ken in the generated sequence in the context of the question. We demonstrate that inte- grating MARS into UE methods results in a universal and significant improvement in UE performance. We conduct experiments using three distinct closed-book question-answering datasets across five popular pre-trained LLMs. Lastly, we validate the efficacy of MARS on a Medical QA dataset.
Yavuz Faruk Bakman
PhD Student in Computer Science Capital One Responsible AI Fellow
My research interests include Trustworthy LLM, Continual Learning and Federated Learning.